In a Data-as-a-Product operating model, the biggest orchestration mistake is treating the platform like a single “master scheduler.” It scales poorly, couples domains, and turns every change into a coordination exercise.
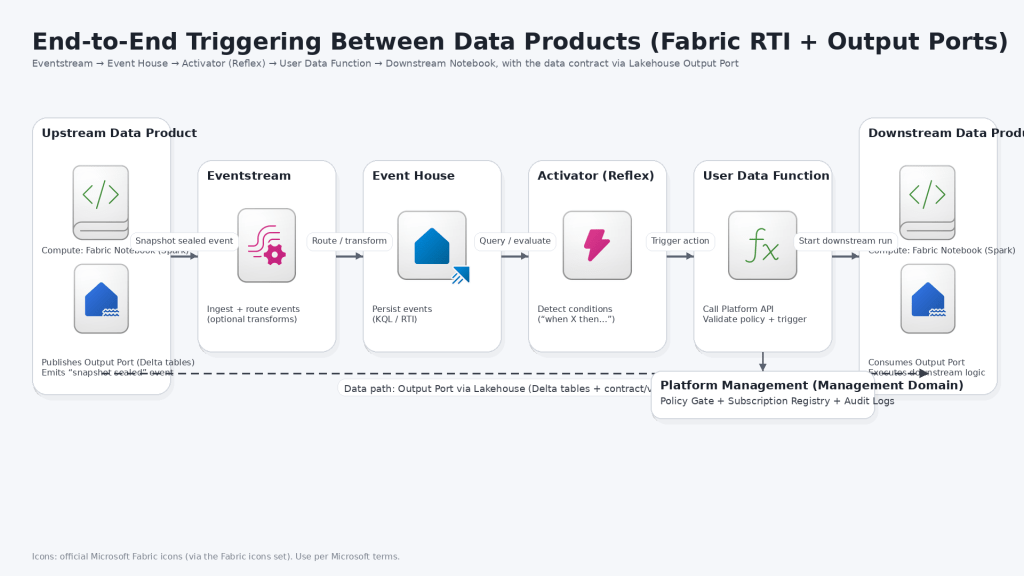
A cleaner approach is signal-driven triggering:
- Upstream data products publish facts about readiness (not “please run job X at 02:00”).
- Downstream data products react only when the contract is compatible and the data is actually usable.
- The platform provides governance, observability, and safety rails—without taking ownership away from domains.
Microsoft Fabric’s Real-Time Intelligence (RTI) workload provides a pragmatic backbone for this pattern using:
Eventstream (ingestion) → Eventhouse (event storage + query) → Activator (rules + actions), complemented by User-Defined Functions in Eventhouse to standardize and enrich readiness signals.
Your data products remain linked through Output Ports implemented as Lakehouse assets (tables/files), which are consumed contract-first.
The pattern at a glance
Components and responsibilities
1) Data Products (Domain-owned)
- Produce data and publish it to an Output Port (Lakehouse-backed).
- Emit a “Snapshot Sealed / Output Ready” event when the output is consumable.
2) Output Ports (Contract boundary)
- Stable identifier + version.
- Clear semantic meaning and expectations (schema/quality/freshness).
3) Eventstream (Ingestion)
- Captures readiness events from many domains/products and forwards them reliably into RTI.
4) Eventhouse (Event storage + query)
- Persists events and enables fast querying.
- Hosts user-defined functions to normalize events, compute derived fields, and keep rules consistent.
5) Activator (Rules + actions)
- Watches for conditions (e.g., “Gold output sealed and quality passed”).
- Triggers downstream actions (webhook, pipeline kickoff, notification, ticket, Service Bus message—whatever your platform standard is).
6) Platform Management (Central governance broker)
- Owns the policy gates: allowed dependencies, no cycles, naming rules, entitlement rules.
- Provides the canonical registry of products, output ports, versions, and subscriptions.
- Optionally exposes a single “Trigger API” so Activator doesn’t need to know downstream implementation details.
End-to-end flow (what actually happens)
Step 1 — Upstream publishes to its Output Port (Lakehouse)
The upstream product writes its output (table/file) into the Lakehouse location representing the Output Port.
Key point: Publishing data and emitting the “ready” signal are separate concerns. The data is the product artifact; the event is the operational signal.
Step 2 — Upstream emits a “SnapshotSealed” event
Once data is successfully written and validated, the upstream emits an event such as:
{
"eventType": "OutputPortSnapshotSealed",
"eventId": "b7a9b2a0-7f2a-4b5f-9e74-3e9d4d2d1b1a",
"occurredAt": "2025-12-18T10:15:42Z",
"producer": {
"dataProduct": "dp.customer.customer360",
"domain": "customer"
},
"outputPort": {
"key": "op.customer.customer360.profile",
"version": "1.2.0",
"stage": "prod"
},
"snapshot": {
"watermark": "2025-12-18T10:00:00Z",
"recordCount": 1842231,
"schemaHash": "sha256:9c8e…",
"quality": {
"status": "passed",
"ruleset": "gold-minimum",
"score": 0.98
}
}
}
Practical advice:
- Always include an idempotency key (
eventId) and a stable snapshot identifier (watermark, batchId, partition). - Include schemaHash and contract version to enable safe downstream validation.
Step 3 — Eventstream ingests and routes into Eventhouse
Eventstream receives the event (from your chosen source) and lands it in Eventhouse for storage and querying.
Step 4 — Eventhouse normalizes via a User-Defined Function
Instead of duplicating transformation logic across rules, define a reusable function that standardizes events.
Example (illustrative) KQL-style function concept:
.create-or-alter function with (folder="dp-signals") NormalizeSnapshotSealed(e:dynamic)
{
project
EventId = tostring(e.eventId),
OccurredAt = todatetime(e.occurredAt),
ProducerDp = tostring(e.producer.dataProduct),
OutputPortKey = tostring(e.outputPort.key),
OutputPortVersion = tostring(e.outputPort.version),
Stage = tostring(e.outputPort.stage),
Watermark = tostring(e.snapshot.watermark),
SchemaHash = tostring(e.snapshot.schemaHash),
QualityStatus = tostring(e.snapshot.quality.status),
RecordCount = tolong(e.snapshot.recordCount)
}
This gives you a consistent “signal table shape” for:
- Activator rules
- ad-hoc debugging queries
- dashboards and SLO tracking (“event-to-ready”, “ready-to-consumed”)
Step 5 — Activator evaluates rules and triggers the next product
A typical rule is:
IF (OutputPortSnapshotSealed AND QualityStatus == passed AND Stage == prod AND Version compatible)
THEN trigger downstream product run for all subscribed consumers.
In practice, the cleanest implementation is:
- Activator calls Platform Management Trigger API with the normalized event.
- Platform Management resolves who is subscribed and what is allowed.
- Platform Management publishes a downstream trigger message (for example onto your existing messaging backbone) or invokes a specific downstream job.
This keeps Activator simple and prevents it from becoming the new “central orchestrator.”
Step 6 — Downstream product executes and reads the Output Port
The downstream product runs its own pipelines/notebooks and reads the upstream Output Port from the Lakehouse using the contract identifiers (key + version + stage).
Why this pattern works for Data Products
It enforces product boundaries
Downstream teams depend on:
- the Output Port contract
- the readiness signal
They do not depend on upstream internals.
It reduces coupling and incident blast radius
Instead of chained pipelines with hidden dependencies, you get:
- explicit subscriptions
- observable edges in the product graph
- policy-enforced constraints (including cycle prevention)
It unlocks real operational governance
Eventhouse becomes your operational truth:
- which products publish reliably
- how often outputs are “sealed”
- how long downstream consumers take to react
- where quality gates fail
Governance “must-haves” (so it stays safe)
- No cycles / no self-consumption
- Platform Management should reject subscriptions that introduce cycles.
- This is non-negotiable once you go event-driven.
- Version compatibility rules
- Activator triggers should check contract version and schema hash before running downstream.
- Treat breaking changes as explicit events, not surprises.
- Idempotent triggering
- Assume events can be duplicated or arrive late.
- Downstream jobs should ignore already-processed
eventId/watermark.
- Stage isolation
- Never mix DEV/Test/Prod signals.
- Add
stageto the event and enforce it in policies.
- SLOs and back-pressure
- If an upstream publishes too frequently, downstream might lag.
- Define “maximum trigger rate” and use buffering (Eventhouse) + controlled replay.
Minimal MVP implementation roadmap
MVP (2–3 weeks of effort in most platforms)
- Define event schema + naming conventions.
- Emit SnapshotSealed from one upstream product.
- Land events in Eventhouse.
- Implement one Activator rule that calls Platform Management “Trigger API”.
- Trigger one downstream product and prove idempotency.
Scale-out
- Add subscription registry in Platform Management.
- Add policy gate (cycle detection, medallion rules, entitlements).
- Add standard UDFs for normalization and derived metrics.
- Add SLO dashboards (publish frequency, quality pass rate, lead time).

Leave a comment